 Frequently Asked Questions
Frequently Asked Questions
See below for some questions you may have related to the project.
What's a message broker, and how can I configure it for my environment?
A message broker allows for the adapters of scientific INTERSECT applications to communicate with one another without worrying about who they communicate with. Only adapters subscribed to the same message broker can communicate with one another. We follow a publish-subscribe model of communication
For easy configuration of a broker environment for development, INTERSECT developers can untilize this broker repository.
What's the dependency tree of our own libraries?
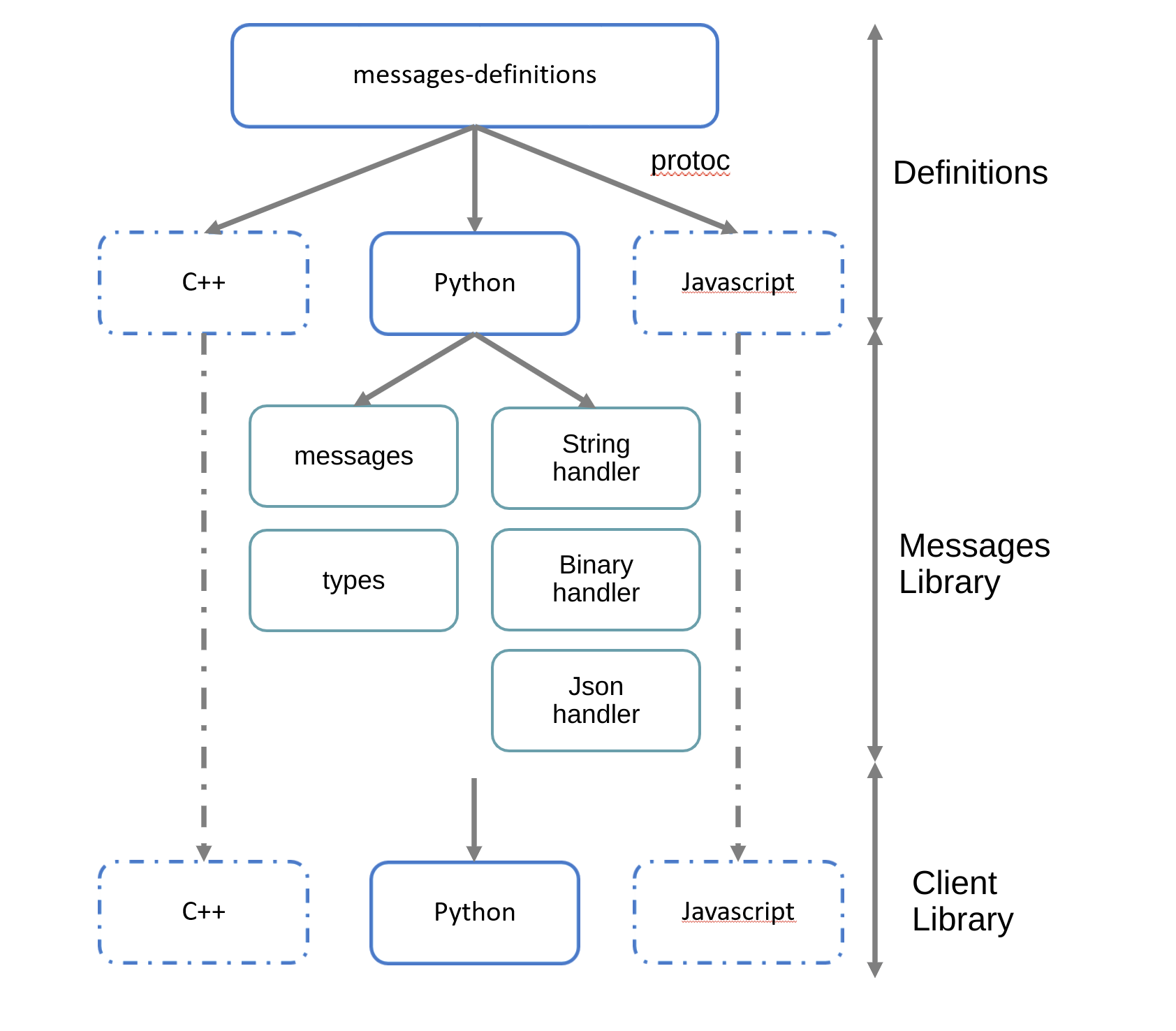
All of INTERSECT will implement a common message specification which can be used regardless of programming language. The messages-definition repository utilizes Google Protocol Buffers to generate ennumerations for a variety of languages; we currently support Python.
We also have a client library which is meant to provide common functionality for interacting with messages and brokers.
Adapters and core INTERSECT microservices will have both the messaging library and the client library as dependencies.
What's a digital twin, what's an adapter, and how are these relevant to SDK developers?
A digital twin is a virtual representation of a scientific instrument, meant to mirror the instrument's deployment environment as closely as possible while allowing developers to easily develop new features. From our perpsective, we should always assume that all digital twins will eventually be maintained by appropriate scientific communities, and not by us.
An adapter is meant to be a standalone application which handles communication between INTERSECT and the digital twin. In some cases, the adapter can be integrated directly in to the digital twin. Adapters will usually both publish and subscribe messages. In the long term, we want adapters to be maintained by the appropriate scientific community, and not us.
What's a core INTERSECT microservice?
Core INTERSECT microservices will usually be associated with persistent data stores providing information about the INTERSECT ecosystem (i.e. system-of-systems, running campaigns). These microservices will interact with the rest of the INTERSECT system via messages sent through the broker, and will also have RESTful APIs accessible for authenticated external users (most commonly through the INTERSECT Dashboard UI). INTERSECT adapters should NOT interact with the REST APIs.
What will I need for deploying applications locally?
We have configurable deployment environments which can help ease the burden of having to set up every application yourself; for more information, check this repository. If you _do_ want to configure the entire environment manually, read below.
If developing any microservice, adapter, or the main SDK library, you'll need to be able to configure the RabbitMQ broker. For development purposes, the easiest way to configure the Broker is to use Docker; the development broker configuration is currently located in this repository.
Some microservices will also require you to be able to configure an appropriate database; see each microservice's README for details on this. These databases should never be accessed by more than one microservice, and should never be assumed to be accessible publicly.
If developing an adapter, you'll need to be able to configure the appropriate digital twin and MinIO. Digital twins should be assumed to require Docker. Provided you can use Docker, MinIO can be configured to run like this:
docker run \ -p 9000:9000 \ -p 9001:9001 \ -e MINIO_ROOT_USER=intersect_user \ -e MINIO_ROOT_PASSWORD=intersect_password \ bitnami/minio:latest
How do I configure a Python project?
If developing microservices/adapters/libraries using Python, our Python stack includes Poetry installation instructions.
Within our repositories, several of our packages will need to be obtained from code.ornl.gov repositories. You will need to set up a Gitlab Personal Access Token with at least read_api permissions. Once you do so and receive the token value, you'll need to run poetry config http-basic.intersect ${YOUR_UCAMS_USERNAME_HERE} ${PERSONAL_ACCESS_TOKEN_HERE}. You should only need to run this once per machine you work on.
Most of our repositories will also include pre-commit hooks used for linting. After running poetry install, run poetry run pre-commit install to automatically install the pre-commit hooks. You should only need to do this once per repository; the hooks run are determined in the .pre-commit-config.yaml file. Pre-commit will fail if any files are changed, but if the linting/formatting tools are able to autofix all errors, you can just git add the changed files to staging and try to commit again.
Copyright © 2023 INTERSECT